ダブリンの気候、最適な服装
ダブリン アドベントカレンダー 24日目です。
さて、今回はそんなアイルランドの首都であるダブリンの、気候や最適な服装について書きます。
ダブリンの気候
ダブリンは緯度が北海道よりも高いので、北海道より寒いのか?と思われがちですが、実はそんなことはなく、 メキシコ湾流の暖流の影響で、冬の気温も東京とそれほど大差なく雪も降ることも滅多にないです。
一方で、夏の7-8月は平均最高気温も20度と東京に比べると比較的過ごしやすいと思います。
日本に比べると、雨の日は圧倒的に多いのですが、ずっと振り続けるということはなく、パラパラと短時間で止むことが多いです。 なので、年間降水量は日本よりも少ないです。

出典 School With
ダブリンでの月別服装
ダブリンに旅行する人にとって、どんな服装でいくか気になるところですよね。 ここでは月別に適切な服装を見ていきます。
ダブリン1月
- 平均最高気温: 7.6度
- 平均最低気温: 2.5度
- 降水量: 69.4mm
最適な服装: セーター、コート、手袋、マフラー
ダブリン2月
- 平均最高気温: 7.5度
- 平均最低気温: 2.5度
- 降水量: 50.4mm
最適な服装: セーター、コート、手袋、マフラー
ダブリン3月
- 平均最高気温: 9.5度
- 平均最低気温: 3.1度
- 降水量: 53.8mm
最適な服装: セーター、コート、手袋、マフラー
ダブリン4月
- 平均最高気温: 11.4度
- 平均最低気温: 4.4度
- 降水量: 50.7mm
最適な服装: セーター、トレーナー
ダブリン5月
- 平均最高気温: 14.2度
- 平均最低気温: 6.8度
- 降水量: 55.1mm
最適な服装: 薄手の長袖、トレーナー
ダブリン6月
- 平均最高気温: 17.2度
- 平均最低気温: 9.6度
- 降水量: 56.0mm
最適な服装: 薄手の長袖、トレーナー
ダブリン7月
- 平均最高気温: 18.9度
- 平均最低気温: 11.4度
- 降水量: 49.9mm
最適な服装: 薄手の長袖、Tシャツ
ダブリン8月
- 平均最高気温: 18.6度
- 平均最低気温: 11.1度
- 降水量: 70.5mm
最適な服装: 薄手の長袖、Tシャツ
ダブリン9月
- 平均最高気温: 16.6度
- 平均最低気温: 9.6度
- 降水量: 66.7mm
最適な服装: 薄手の長袖、トレーナー
ダブリン10月
- 平均最高気温: 13.7度
- 平均最低気温: 7.6度
- 降水量: 69.7mm
最適な服装: セーター、トレーナー
ダブリン11月
- 平均最高気温: 9.8度
- 平均最低気温: 4.2度
- 降水量: 64.7mm
最適な服装: セーター、コート、手袋、マフラー
ダブリン12月
- 平均最高気温: 8.4度
- 平均最低気温: 3.4度
- 降水量: 75.6mm
最適な服装: セーター、コート、手袋、マフラー
まとめ
以上ダブリンの気候と、最適な服装でした。旅行に行く際に参考にしてみてください。
気候を考えると夏は暑くて冬は寒い東京に比べるとダブリンは非常に魅力的な都市なのではないでしょうか?
さてダブリン アドベントカレンダーの大トリは現在ダブリンに滞在中の @tinagaki さんです!! 楽しみですね。
参考
と、ダブリンのことについてつらつら書きましたが、 私はダブリンはおろかアイルランドに行ったことないのですがね。
Macbook Airのバッテリーを自力で交換した
僕のMacはMacBook Air2014年モデル(11-inch, Early 2014)をCPUとメモリをカスタマイズしており、購入して3年ぐらい経つのですが、最近バッテリーアイコンに怪しい表示がされるようになった。

ん?バッテリーの交換修理?
調べてみるとバッテリーの状態は以下の4つに別れるらしい。
正常:バッテリーは正常に機能しています。
間もなく交換:バッテリーは正常に機能していますが、蓄電能力が新品時と比較して低下しています。メニューバーに表示されるバッテリー状況を定期的に確認し、バッテリーの状態に気を配っておいてください。
今すぐ交換:バッテリーは正常に機能していますが、蓄電能力が新品時と比較して大幅に低下しています。コンピュータを使い続けても安全面に支障はありませんが、充電能力の低下のせいで作業効率が悪くなるようであれば、Apple Store 直営店または Apple 正規サービスプロバイダにお持ちください。
バッテリーの交換修理:バッテリーは正常に機能していません。適正な電源アダプタに接続している間は Mac を問題なくお使いいただけますが、できるだけ早く Apple Store 直営店または Apple 正規サービスプロバイダにお持ちください。
とにかく一番悪い状態というのはわかった。ずっと繋ぎっぱなしなのが悪いのかな?

充放電数が600回超えている。
↑によると僕のMacは最大1000回いけるっぽい。まあ半分超えたしこんなものなのかな?
電源アダプターに接続していれば問題ないけど、持ち歩くことも多いので、バッテリー修理することにする。
Apple StoreでMacbook Airのバッテリー交換する場合
Apple Storeを使用する場合は12,800円するようです。 まあ公式だとこんなものか。
自力でMacbook Airのバッテリー交換する場合
Amazonを探すとMacbook Airに適合するバッテリーが売っている。

SLODA 交換用バッテリーApple用MacBook Air 11" A1495 A1406バッテリー[リチウムポリマー、7.6V、5200mAh]
- 出版社/メーカー: SLODA
- メディア: エレクトロニクス
- この商品を含むブログを見る
値段は6,299円!! 交換の方法を調べてみると、Macbook Airの裏蓋開けて、余計なパーツを外すことなくバッテリー交換できるらしい。
誰でも交換できそうなので、こちらの方法でMacbook Airのバッテリー交換することにした。 ちなみにこちらの商品は専用のドライバーも同封しているため、これを買うだけでOK。
自力でMacbook Airのバッテリーを交換してみる
早速購入して届いた。


こんな感じ。
六星と五星のドライバー2つ同封されている。
MacBookの電源を切ってから裏蓋を分解していく。

こんな感じ。結構ホコリ溜まってる。 軽くホコリを取ってから、バッテリーのネジを外していく。

本体とバッテリーをつなぐ、電源コネクターは軽く上に持ち上げるとかんたんに外れる。
これだけでOK。
あとは購入したバッテリーを交換して、ネジをしめるだけ。
ちゃんとバッテリーが認識されるか?
ちゃんと電源がついた。

警告も消えた。

充放電回数もリセットされた。 今のところは問題なく使えている。
まとめ
MacbookAirのバッテリーは自分で簡単に交換できることがわかった。
SLODA 交換用バッテリーApple用MacBook Air 11" A1495 A1406バッテリー[リチウムポリマー、7.6V、5200mAh]
- 出版社/メーカー: SLODA
- メディア: エレクトロニクス
- この商品を含むブログを見る
【PHP】OpauthでLINEログインを簡単に実装する
PHPのSNSログインライブラリ、OpauthがLINEログインに対応しました! Opauthを使えば簡単にLINEログインも実装できます。 バグがあったらPRお願いします。
PHPでLINEログインを実装してみる
LINEログイン準備編
ログイン後にアカウント情報、企業情報を埋めます。

LINEログインの説明を読んだあと、ビジネスアカウントの作成をします。

ここで設定した情報がLINEログインする際に表示される情報になります。
LINEログインアカウントの作成が終わったら、「Basic Information」をクリック
Channel IDとChannnel Secretをメモしましょう。

次に「Technical configuration」をクリック

ここでcallback URLを指定します。
※ちなみにLINEログインはhttpsでなければなりません。ご注意ください。
今回のcallbackURLはhttps://example.com/line/oauth2callbackとします。
これで準備はおしまいです。次に実装編です。
LINEログイン実装編
OpauthのLINE Strategyをインストール
composerを利用してインストールします。
composer require opauth/line
今回はPHPのマイクロフレームワークであるsilexで試してみたいと思います。
composer require silex/silex
設定ファイルの作成
config.phpとして下記の様にしてください
<?php
$config = [
'security_salt' => 'hogehogeyudsuzuk', // ランダムな文字列
'Strategy' => [
'LINE' => [
'channel_id' => 'CHANNEL_ID',
'channel_secret' => 'CHANNEL_SECRET',
]
],
];
index.phpとして下記のようにしてください
<?php
require_once(__DIR__ . '/vendor/autoload.php');
$app = new Silex\Application();
// LINEログインURL
$app->get('/line', function () {
require_once(__DIR__ . '/config.php');
new Opauth($config);
return 'OK';
});
// LINEログインとしてのコールバック
$app->get('/line/oauth2callback', function () {
require_once(__DIR__ . '/config.php');
new Opauth($config);
return 'OK';
});
// コールバック。すでに認証情報がsessionに入っています。
$app->get('/callback', function () {
session_start();
return print_r($_SESSION,true);
});
$app->run();
これでLINEログインの実装は完了です。
https://example.com/line にアクセスするとLINEの認証画面が表示され、ログインするとSESSIONの中身が表示されます。
お疲れ様でした!!
RubyのOmniAuthのPHP版、Opauthのコミッターになった。
諸事情により複数SNS連携ログインをPHPで実装しなくてはならなくなりました。
RubyのOmniAuthのPHP版と謳っていた、Opauthを使ってみたのですが、改良の余地が色々ありました。
なのでリポジトリ上で色々活動していたら、Opauthの管理者であり、Blockchain developerである、uzynさんにコミット権限を付与していただき、晴れてコミッターになることができました!
何気にOSSのコミッターは初めてなのですが、より良いライブラリになるように頑張りたいと思います。
今年は他の言語を学ぶつもりで、プライベートではPHPを触らない予定だったのですが、ガッツリ触ることになりそうですw
そうそう、第10回のrehash.fm(テック系ポッドキャスト)で、WordPressの脆弱性や、Apache Struts 2の脆弱性について話をしてきたので お時間のある方はぜひお聞きください。
【機械学習】サポートベクターマシン(SVM)を使用して、乳癌かどうか調べてみる
サポートベクターマシン(SVM)について
サポートベクターマシン(以下SVM)とは、教師ありの機械学習の一手法です。 SVMは、現在知られている機械学習の手法の中で、認識性能が優れた学習モデルの一つです。 その理由は、未学習データに対して高い識別性能を得るための工夫があるためです。 学習サンプルから「マージン最大化」という基準で線形入力素子を利用して 2 クラスのパターン識別器を構成します。
SVMの具体的な例
○と●という2種類のデータがあるとして、そのデータをどのように分けるかを考えたとき、境界線を引くことが考えられます。
下記のグラフを見てみましょう。
- H3は二つのクラスのいくつかの点を正しく分類していません。
- H1とH2は二つのクラスのいくつかの点を正しく分類しています。
- H2がH1よりもっと大きいマージンを持って分類することを確認することができます。

※wikipediaより。
この識別平面からもっとも近い既知パターンとの距離(マージン)を最大になるように決定するのが最良の結果となります。 これがSVMの「マージン最大化」という方針です。 SVMを使えば未知のパターンに対しても正しく分類できる確率が高いと言われてます。
PHPでSVMを使えるようにする
CentOSでインストールする場合はこんな感じです。
sudo yum install libsvm libsvm-devel sudo pecl install svm-0.1.9
php.iniに下記を加える
extension=svm.so
これで準備ができました。
SVMを使って乳がんかどうかを調べる
スタンフォード大学の機械学習コースでも同じような例があったので試してみます。
乳がんであることは色んな要因があると考えられます。
今回はSVMのテストなので、2次元ベクトルとして、年齢としこりの大きさで考えてみましょう。
イメージが下記のグラフです。
X軸がしこりの大きさ、Y軸が年齢、赤が悪性、青が良性です。

実際のサンプルデータがないので便宜的に右上が悪性、左下が良性としてプログラムで作成してしまいます。
<?php
$data = [];
for ($i = 0;$i < 100;$i++) {
// 良性
$size = mt_rand(0,4);
$age = mt_rand(0,40);
$data[] = [0,$size,$age];
// 悪性
$size = mt_rand(5, 10);
$age = mt_rand(50, 80);
$data[] = [1,$size,$age];
}
// データを学習してモデルを生成
$svm = new SVM();
$model = $svm->train($data);
// 良性テスト
$pre = $model->predict([1,30]);
echo $pre. "\n";
// 悪性テスト
$pre = $model->predict([8,70]);
echo $pre. "\n";
実行してみます。
$ php svm-test.php 0 1
うまくいきましたね!実際は乳房の腫瘍の塊の厚み、腫瘍の細胞のサイズの均一性、腫瘍の細胞の形状の均一性などなど、様々な要素が絡み合いますが、基本的な考え方は一緒です。 実際のデータを元に算出してみたいですね。
【機械学習】ニューラルネットワークを利用して自分の好みの女性を学習させる
ニューラルネットワークとは?
脳内には多数のニューロンと呼ばれる神経細胞があります。それぞれのニューロンは、他のニューロンから信号を受け付け,他のニューロンへ信号を受け渡しています。脳は、この信号の流れによって、様々な情報処理を行っています。 この仕組みをコンピュータ内に実現しようとしたものがニューラルネットワークです。
たとえば、入力層に学習させたいデータの特徴を入力します。 すると、入力層、中間層、出力層を通って、結果が出力されます。
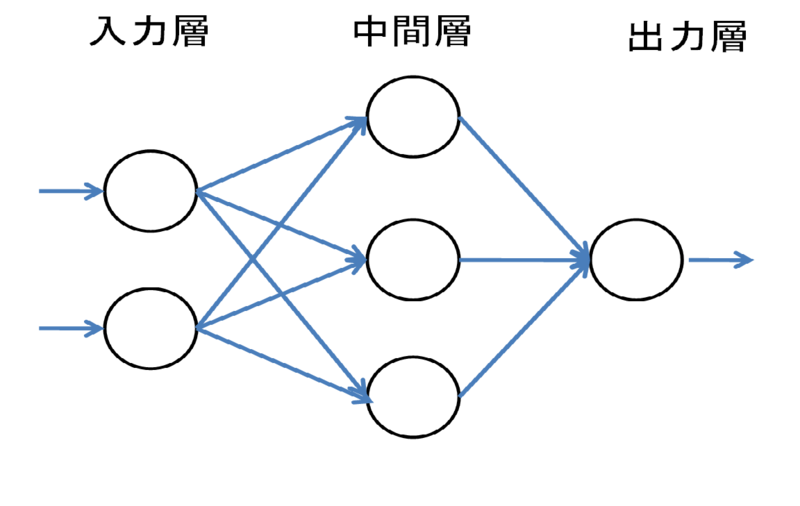
ニューロンのモデル化
ニューロンの基本的な働きは信号の入力と出力だけです。 ここで重要になるのが、入力された信号をそのまま出力するのではなく一定の閾値を超えたときのみ出力(発火)されます。
ニューロンにはそれぞれ信号伝達の効率がバラバラです。そこでそれぞれの入力に対し結合荷重を設定します。 そしてその重み付きの入力の総和が各ニューロンに設定されている閾値を超えたとき、発火したとして、他ニューロンに信号を送ります。 コンピュータ上での実現のため、簡単化のため0を信号が無い、1を信号がある状態とします。
数式で表してみます。
\( i \)番目のニューロンからの入力信号を\( x_i \)、それぞれの荷重を\( w_i \)とすると他ニューロンからの入力信号の総和は、
となります。 入力信号を受けっとったニューロンは、その入力値が一定の閾値\( θ \)を超えたときに発火するので、次のように表せます。
ここで関数 \( f_k \)は入力値に対し発火するかしないかなので1か0を返却する関数です。このような関数は、ステップ関数またはヘビサイド関数と呼ばれています。関数は次のようになります。
これがニューロンモデルです。
FANNについて
PHPでニューラルネットワークを扱うためにはFANNを使う必要があります。
Fast Artificial Neural Network Library (FANN)
FANNはC言語で書かれていて主に次の特徴があります。
MacOSXへFANNをインストール
$ brew install homebrew/science/fann $ pecl install fann
php.iniに下記を追記
extension=fann.so
確認
php -i |grep fann
では次にFANNを使って自分の好みの女性を学習させてみましょう
自分の好みの女性かそうでないかを分類する
学習データを集める
まず教師データとして、大量の女性の画像が必要になります。 集め方はここでは触れませんが、僕は某ユニコーン企業のサイトから拝借させていただきました。
それぞれlikeとnopeというフォルダを用意し、手動で分類してください。それぞれ200枚ぐらい用意してみると良いかも。 更にテスト用にlike-testとnope-testというフォルダも用意しテスト用の画像としてそこにも20枚ぐらいいれておいてください。
学習データの作成
画像の分類はカラーヒストグラムを作成し、ニューラルネットワークで判定したいと思います。 カラーヒストグラムについては下記の記事を参照してください。
カラーヒストグラムを作成するプログラム(histogram-ib.inc.php)
<?php
function make_histogram($path, $debug = true) {
if ($debug) {
echo "histogram: $path\n";
}
$im_big = imagecreatefromjpeg($path);
$sx_big = imagesx($im_big);
$sy_big = imagesy($im_big);
$sx = 256;
$sy = 192;
$im = imagecreatetruecolor($sx, $sy);
imagecopyresampled($im, $im_big, 0, 0, 0, 0, $sx, $sy, $sx_big, $sy_big);
$his = array_fill(0, 64, 0);
for ($y = 0;$y < $sy;$y++) {
for ($x = 0;$x < $sx;$x++) {
$rgb = imagecolorat($im, $x, $y);
$no = rgb2no($rgb);
$his[$no]++;
}
}
$pixels = $sx * $sy;
for ($i = 0; $i < 64; $i++) {
$his[$i] = $his[$i] / $pixels;
}
imagedestroy($im_big);
imagedestroy($im);
return $his;
}
function rgb2no($rgb) {
$r = ($rgb >> 16) & 0xFF;
$g = ($rgb >> 8) & 0xFF;
$b = $rgb & 0xFF;
$rn = floor($r / 64);
$gn = floor($g / 64);
$bn = floor($b / 64);
return 16 * $rn + 4 * $gn + $bn;
}
ヒストグラムデータからFANNの学習用データを生成するプログラム(gen-data.php)
<?php
require_once 'histogram-lib.inc.php';
$favorite_type = [
"like" => "1 0",
"nope" => "0 1",
];
gen_data("", 40);
gen_data("-test", 14);
echo "ok\n";
function gen_data($dir_type, $count) {
$data = '';
$types = ['like', 'nope'];
$cnt = 0;
foreach ($types as $type) {
$type_list = glob("{$type}{$dir_type}/*jpg");
shuffle($type_list);
$type_list = array_slice($type_list, 0, $count);
$cnt += count($type_list);
$data .= gen_fann_data($type_list, $type);
}
$data = "$cnt 64 2\n" . $data;
file_put_contents("type{$dir_type}.dat", $data);
}
function gen_fann_data($list, $type) {
global $favorite_type;
$out = $favorite_type[$type];
$data = '';
foreach ($list as $f) {
$his = make_histogram($f);
$data .= implode(' ', $his) . "\n";
$data .= $out . "\n";
}
return $data;
}
これを実行するとtype.datとtype-test.datというデータが生成されます。
$ php gen-data.php histogram: like/0228.jpg histogram: like/0060.jpg histogram: like/0295.jpg * * * ok
生成された学習用データを実際にFANNで学習して、テストデータで判定してみます(train.php)
<?php
$num_layers = 3;
$num_input = 64;
$num_neuros_hidden = 3;
$num_output = 2;
$ann = fann_create_standard(
$num_layers, $num_input,
$num_neuros_hidden, $num_output
);
if (!$ann) {
die("FANNの初期化に失敗");
}
fann_set_activation_function_hidden($ann, FANN_SIGMOID_SYMMETRIC);
fann_set_activation_function_output($ann, FANN_SIGMOID_SYMMETRIC);
echo "学習します\n";
$desired_error = 0.0001;
$max_epochs = 500000;
$epochs_between_reports = 1000;
fann_train_on_file($ann, "type.dat", $max_epochs, $epochs_between_reports, $desired_error);
fann_save($ann, 'type.net');
echo "テストします\n";
$favorite_data = [
"1 0" => 'like',
"0 1" => 'nope',
];
$favorite_index = ["like", "nope"];
$testdata = explode("\n", file_get_contents("type-test.dat"));
array_shift($testdata);
$total = $ok = 0;
while ($testdata) {
$s = array_shift($testdata);
if ($s == "") continue;
$data = explode(" ", $s);
$label = array_shift($testdata);
$label_desc = $favorite_data[$label];
$r = fann_run($ann, $data);
$v = $favorite_index[array_max_index($r)];
echo "- $label_desc = $v\n";
if ($label_desc == $v) $ok++;
$total++;
}
$pre = floor($ok / $total * 100);
echo "結果: $ok/$total = $pre%\n";
function array_max_index($a) {
$mv = -1;
$mi = -1;
foreach ($a as $i => $v) {
if ($mv < $v) {
$mv = $v;
$mi = $i;
}
}
return $mi;
}
実行してみましょう
$ php train.php 学習します テストします - like = like - like = like - like = like - like = like * * * 結果: 21/28 = 75%
ってことでわりとまずまずな数値が出たのではないでしょうか?
簡単にWEBのインターフェイスも作ってみました。


なるほどな結果になりましたね!
カラーヒストグラムを利用した類似画像検索システムの作り方
最近Machine Learning(機械学習)を勉強することが多いのですが、そこに引きづられて類似画像検索について勉強する機会があったので、その内容についてまとめます。
画像検索ではクエリにテキストを入れてテキストに関連した画像を検索します。 一方、類似画像検索ではクエリに画像を与えて似た画像を検索します。 検索クエリに画像をアップロードすることが特徴です。
この分野をCBIR(Content-based image retrieval)と呼び1992年から研究されているそうです。
検索手法は沢山ありますが、今回は、画像の色に着目して、類似画像検索システムを作ってみたいと思います。
カラーヒストグラムとは
色は色の三原色である、赤緑青、所謂RGBで表せます。 そのRGBを使って、画像中にRGBの各色が何ピクセルあるか数えて作成した棒グラフです。 たとえば、

のカラーヒストグラムを作成すると

このように描写できます。
画像を減色して計算する
上記のグラフを見て気づいた方がいるかもしれませんが、減色して計算しています。
通常色はRGBの各8ビット、つまり256通りですので、表示できる色数は\( 256^{3} \) で約17,000,000通りあります。 これはあまりにも多すぎて計算量が膨大になってしまいます。 ですので、RGBを各2ビット、つまり4通り、\( 4^{3}=64 \) 通りまで減色。64次元のベクトルで計算できるようにしています。
画像の類似度の算出
画像Aのカラー値\( i \) のピクセルの個数を\( AH_i \)、2枚目の画像のカラー値\( i \) のピクセルの個数を\( BH_i \)とします。各カラー値\( min(AH_i,BH_i) \) についてを求めます。 \( min(A,B) \) とは\( A \)と\( B \)で小さい方を返す関数です。 これを全部のカラー値で足すと
となり\( D \) をヒストグラムインタセクションいいます。
この値が大きくなればなるほど、2つの画像は類似しているということになります。
PHPによるサンプルプログラム
RGBから64色に減色するプログラム
<?php
/**
* ヒストグラムのビンを計算
* @param $rgb
* @return int
*/
function rgb2no($rgb) {
$r = ($rgb >> 16) & 0xFF;
$g = ($rgb >> 8) & 0xFF;
$b = $rgb & 0xFF;
$rn = floor($r / 64);
$gn = floor($g / 64);
$bn = floor($b / 64);
return 16 * $rn + 4 * $gn + $bn;
}
カラーヒストグラム作成プログラム
/**
* 画像からカラーヒストグラムを作成(csv形式)
* @param $path 画像保存先
* @param bool $cache
* @return array
*/
function makeHistogram($path, $cache = TRUE) {
// 結果を保存するファイル
$csvfile = preg_replace('/\.(jpg|jpeg)$/', '-his.csv', $path);
if ($cache) { // ヒストグラムのキャッシュを使うか
if (file_exists($csvfile)) {
$s = file_get_contents($csvfile);
return explode(",", $s);
}
}
$im = imagecreatefromjpeg($path);
$sx = imagesx($im);
$sy = imagesy($im);
// ピクセルを数える
$his = array_fill(0, 64, 0);
for ($y = 0; $y < $sy; $y++) {
for ($x = 0; $x < $sx; $x++) {
$rgb = imagecolorat($im, $x, $y);
$no = rgb2no($rgb);
$his[$no]++;
}
}
// 8bitに正規化
$pixels = $sx * $sy;
for ($i = 0; $i < 64; $i++) {
$his[$i] = floor(256 * $his[$i] / $pixels);
}
file_put_contents($csvfile, implode(",", $his));
return $his;
}
2つの画像から類似度を調べる
// $AHは画像Aのカラーヒストグラム、$BHは画像Bのカラーヒストグラム
$sum = 0;
for ($i = 0;$i < 64;$i++) {
$sum += $min($AH[$i], $BH[$i]);
}
これらのロジックに基いて、予め用意しておいた画像を検索対象にして、検索してみましょう。 すると下記のような結果が得られます。 左上から順に類似度が高いものになります。

類似画像が検索できましたね!
参考文献
類似画像検索システムを作ろう - 人工知能に関する断創録
http://web.tuat.ac.jp/~s-hotta/gke/ch4/index.html